
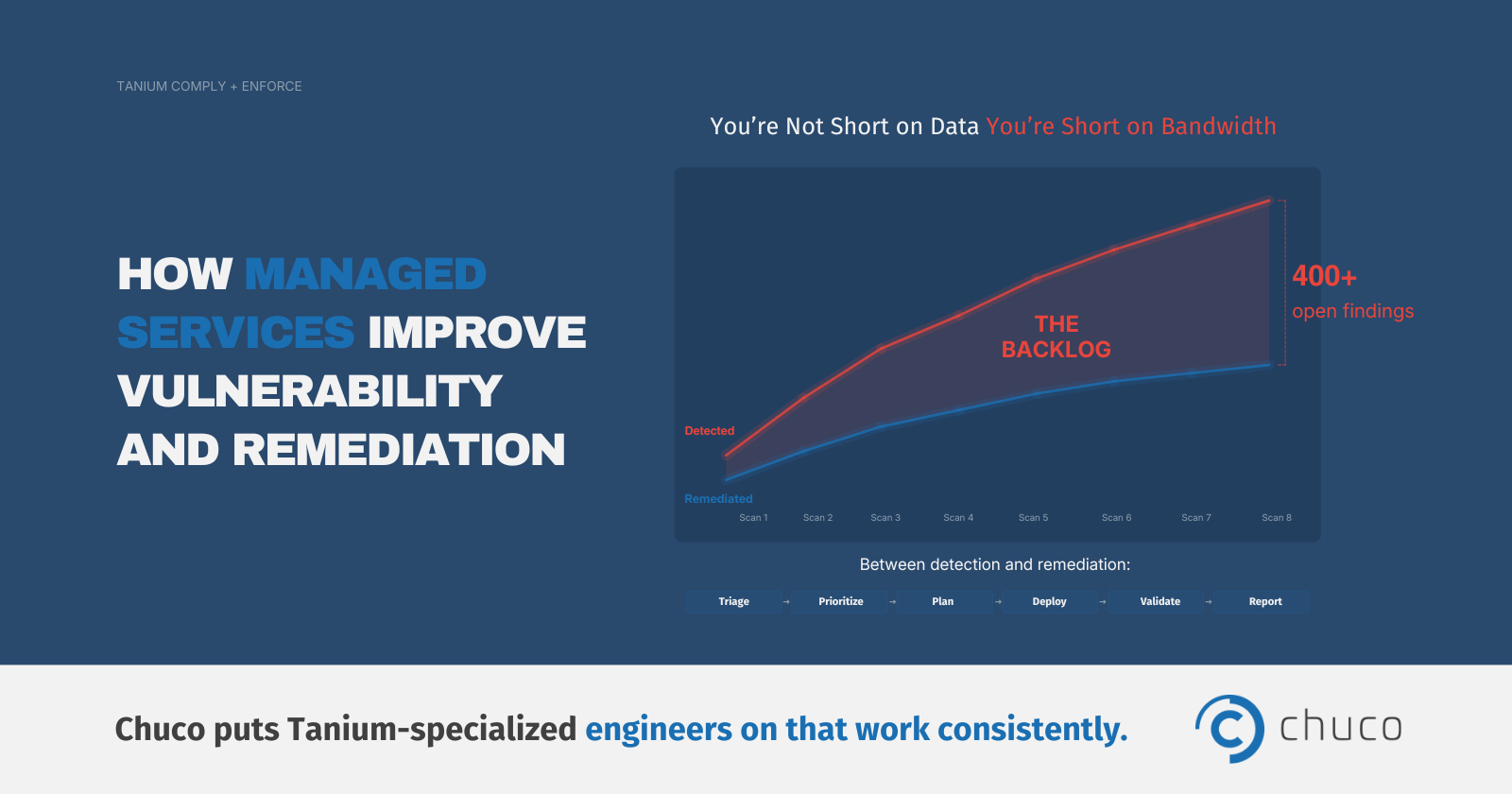
How Managed Services Improve Vulnerability and Remediation
Most organizations can detect vulnerabilities. The hard part is remediating them at scale before they become exposure. Here’s how managed services close that gap.
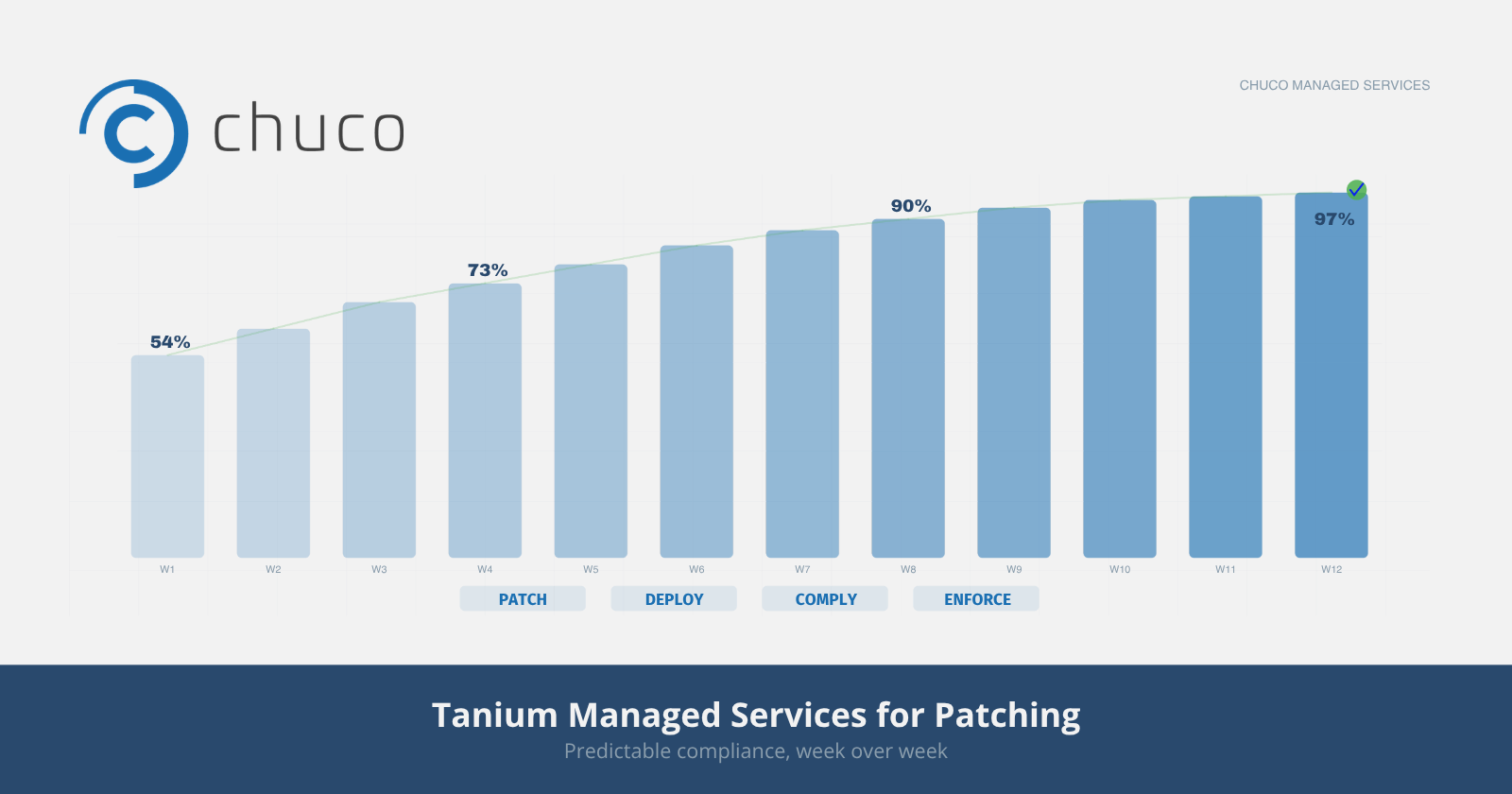
Top Tanium Managed Services for Patching and Updates
Your team has the skills — what they don’t always have is the bandwidth, Tanium-specific depth, and capacity to deliver consistent results at scale. Here’s how Chuco’s managed services for Tanium patching close that gap.
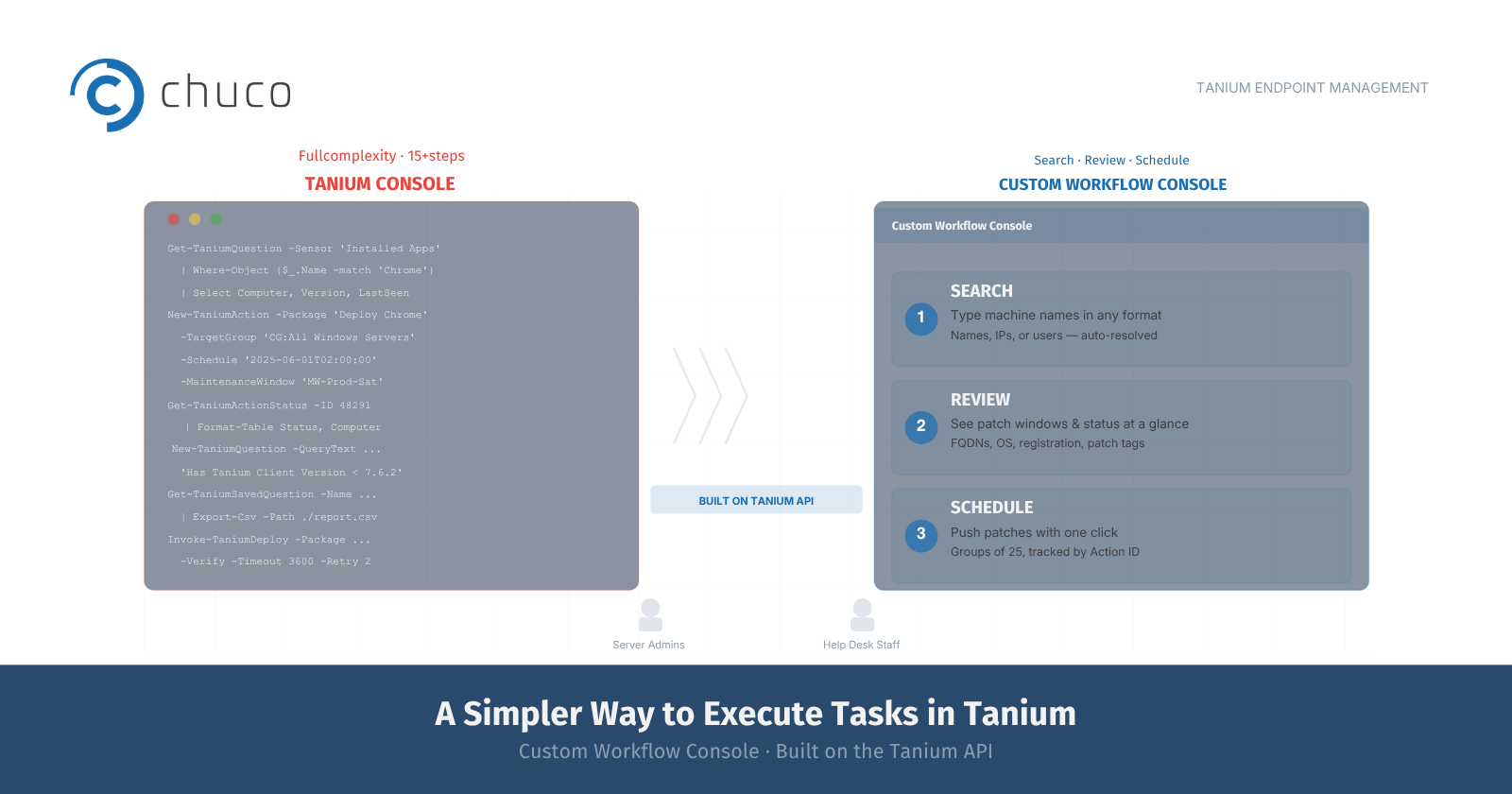
A Simpler Way to Execute Tasks in Tanium
You can’t secure what you can’t see — but what happens when the tools providing that visibility are the ones failing? We took that question to Tanium Atlas.